The Compositionality Gap and the Compositional Celebrities Dataset
As language models grow in size they know more, but do they get better at reasoning? To test GPT-3, we generated lots of questions such as “What is the calling code of the birthplace of Adele?”.
We show that as GPT-3 size grows, it does not improve its reasoning abilities on these types of questions.
Compositional Celebrities
To test the reasoning abilities of LMs we built Compositional Celebrities, a dataset of 8.6k questions in 17 different categories.

These questions all require first retreiving 2 facts and then conducting some basic reasoning about them. For example, to answer “What is the calling code of the birthplace of Adele?” a model must first know that Adele was born in the UK and then should figure out that it needs to return the calling code of the UK- +44.
The reasoning required to answer them is simple, and the basic facts are commonly appearing (since they are either related to celebrities or their birth country or year), but we believe that these 2-hop questions have never previously appeared in any text that could be in the training set of an LM.
The Compositionality Gap
We can check the accuracy on these compositional questions (blue) or the accuracy for each pair of sub-questions separately (i.e. “What is the birthplace of Adele?” & “What is the calling code of the U.K.?”).
The surprising result we uncovered is that the compositionality gap doesn’t narrow with scale!
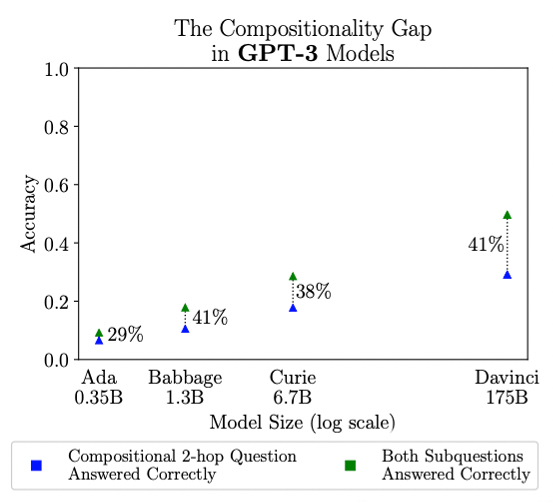
The compositionality gap is the fraction of compositional questions that GPT-3 can’t answer even though it can separately answer the two sub-questions that make up the compositional question.
As GPT-3 gets larger it’s remembering more facts but it’s not able to compose ~40% of these fact pairs, at all model sizes between 1B to 175B parameters! Maybe scale can’t solve everything?
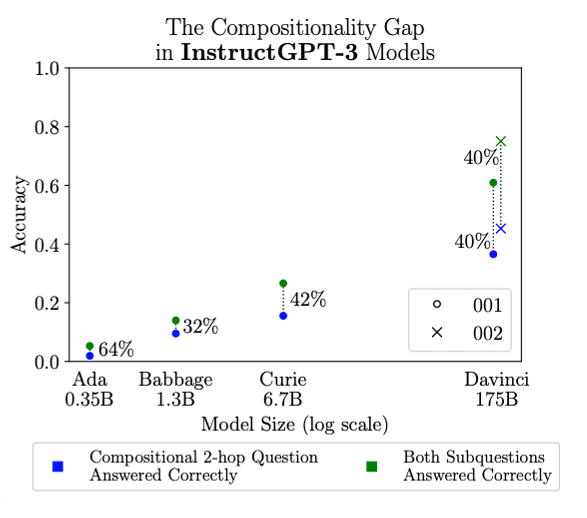
This surprising result also occurs in the InstructGPT-3 family of models! The compositionality gap stays around 40% no matter how much we increase model size.
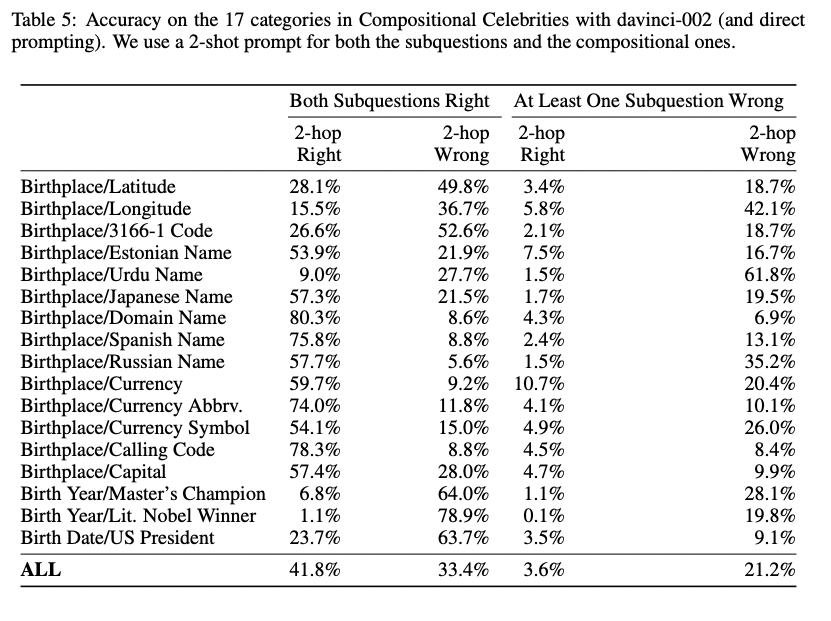
In the table below, we zoom in on the results for the best GPT-3 model, davinci-002. Some compositional question categories are really easy for it, like Birthplace/Domain Name (80% acc), but some are super hard, like Birth Year/Lit. Nobel Winner (1% acc). We’re not quite sure why.
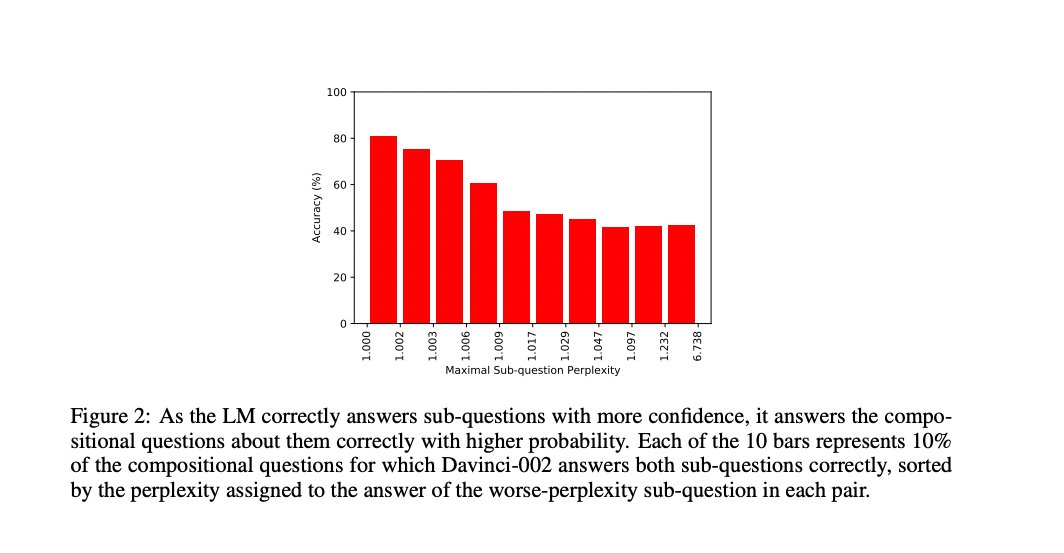
And finally, the figure below presents an interesting finding: when GPT-3 (davinci-002) is very confident about two facts, it will be able to answer the compositional 2-hop question about them with much higher probability!
Our paper is available here, and the Compositional Celebrities dataset is available on GitHub.